Self-Reasoning Tokens, teaching models to think ahead.

What is the mathematical formulation of reasoning? How can we make LLMs like chatGPT think before they speak? And how can we make that baked into the model so it can learn to think in a self-supervised way without having to "explain it step by step" (or another famous prompt we use when we want to improve chatGPT performance drastically)? How can we teach models to think ahead? I will share with you the results of some experiments that may cast light on the path of "Reasoning Tokens."
Introduction
As the authors of "Interpretability in the wild" have taught us, from looking inside transformers, we know that the computation of the next token includes some information computed in previous steps. This may seem obvious at first glance, but there is more to this affirmation than what meets the eye. This means the language model expends some internal "cognitive power" processing and storing information that will be used, not for predicting the very next token but 2, 3, or even 10 tokens ahead.

As we can see from the image above, the attention heads produce computations that will be helpful only in the far future, and even some calculations that "headge" against the wrong answers, exposed in the paper as "Negative Name Mover Heads" or attention heads that suppress specific tokens.

Further work has shown that LLMs indeed plan for future tokens. In the paper "Do Language Models Plan for Future Tokens?" the authors carefully crafted a mathematical formulation to impede what they call "Pre-Caching," or the ability of the model to make intermediary computations that would be useful beyond the very next token. Their experiments found a small performance gap when the model was "myopic" or incapable of planning for future tokens. This is promising but could be better. This indicates that while GPTs plan ahead, most of their power is used to predict only the next word in the sequence. As a sanity check, this gap should increase as the length of the predicted text grows because the model would have more tokens to produce said computations, and indeed, that was what they found in the paper.
How do we leverage that?
What if we incentivized those intermediary calculations, which are useful only in future tokens, teaching the model to think ahead in a self-supervised way? It turns out that the formulation for such a task doesn't need to be that complicated.
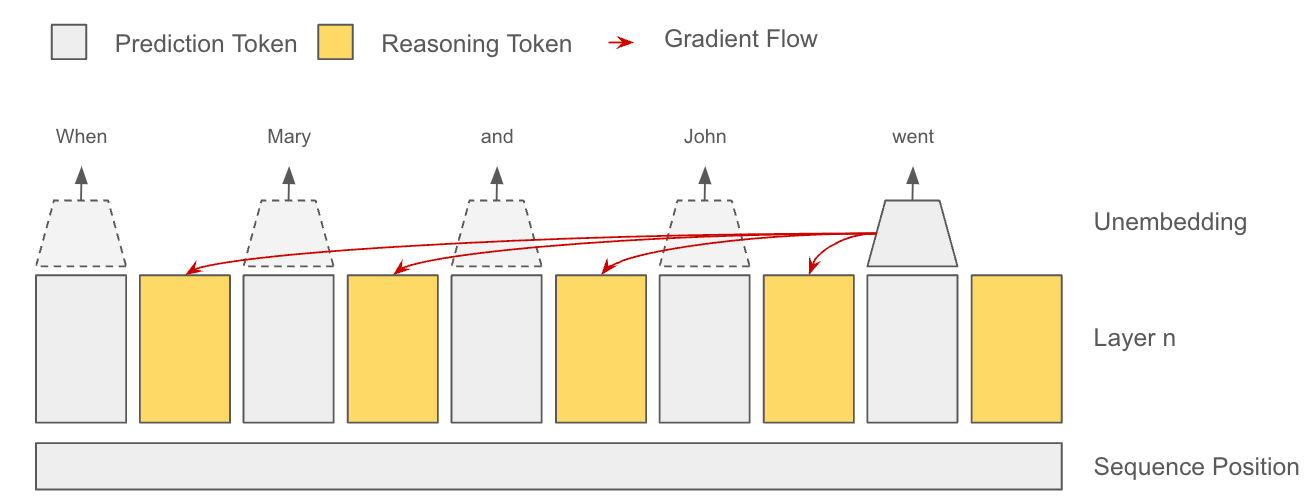
In this first experiment, we introduce reasoning tokens! The model will produce two tokens for each token in the original sequence. As usual, the first token will be used to predict the next token. The second token, however, duplicates the input of the first one and does not receive a gradient "answer" from the very next token, only from future tokens; in fact, this token doesn't even participate in the calculation of the very next token. This incentivizes the model to "pre-cache" or only put information that is useful for the future in this spot. But talk is cheap. Show me the results.
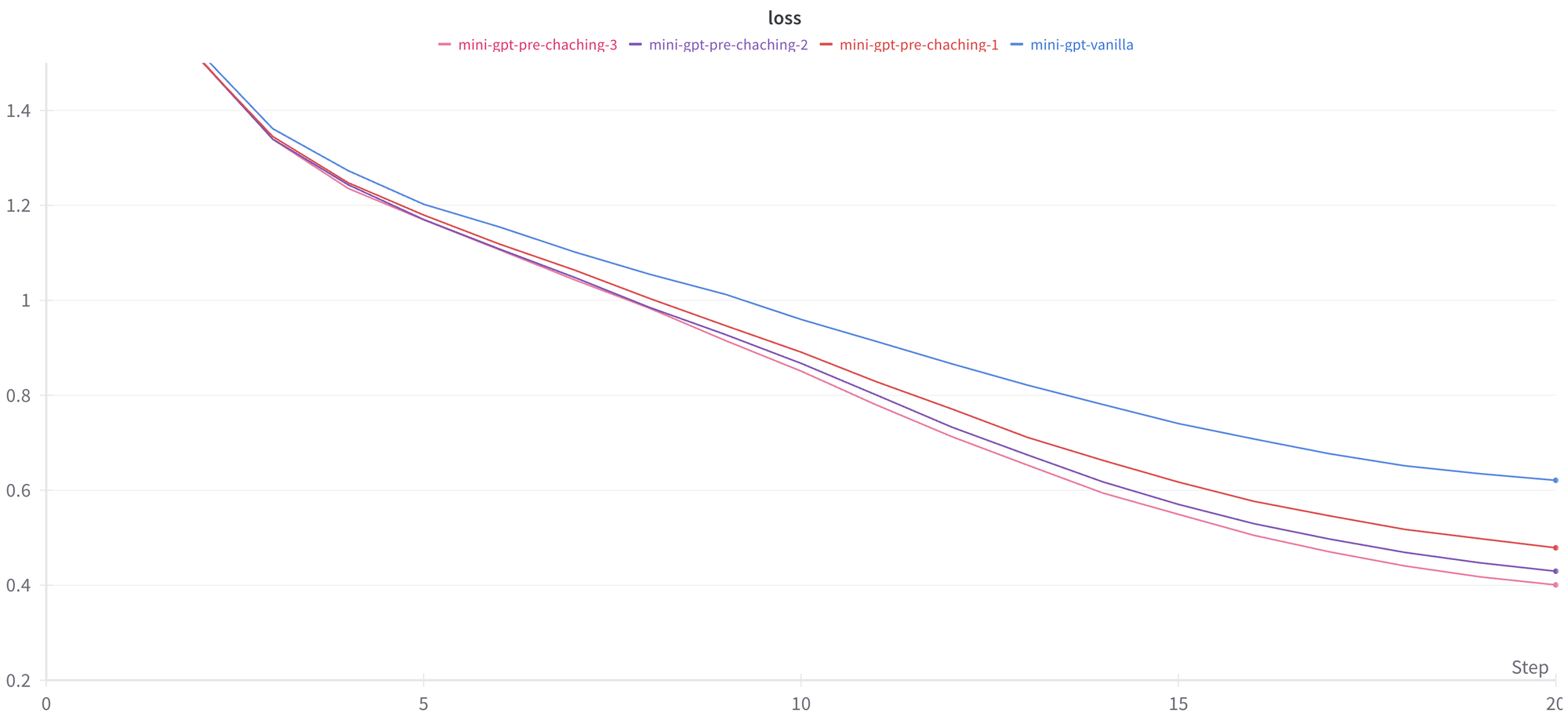
And the results are very promising, showing a reduction of 35% in the loss! From 0.621 to 0.401. The experiment also shows that the model benefits from having multiple tokens to do its "reasoning," forecasting the capability to form long-range dependencies. This validates the hypothesis that we can teach the models to plan for the future, an important first step to get to reasoning.
A GPT-2 Small (124M params) model was also trained on 300B tokens of the "Open Web Text Corpus," and its results were also very promising, resulting in a 0.04 validation loss reduction from 2.85 to 2.81. In context, going from GPT-2 Large (~700M) to GPT-2 XL (1.5B) drops the validation loss by 0.13 in the same dataset. All training code was derived from Andrej Karpathy amazing GPT-2 implementation.

What is next for Reasoning Tokens?
Currently, I'm experimenting with reasoning tokens in fine-tuned instruction following models, where planning can be much more useful. The formulation is very close to the first experiment. Still, this time, the model can choose when this internal reasoning will start, allowing it to choose when to reason before producing the next word in the sequence.

The hypothesis being tested is that the addition of Reasoning Tokens can substitute and outperform models where a "step by step" explanation is included in the training phase. This would be useful because those explanations are expensive to produce/obtain. Although such explanations can be useful to the model, gradient descent could find other ways to do that reasoning using all the internal mathematical dimensions of the model in a way that does not necessarily make sense to us. It would be a great fit for "Mixture of Experts" (MoE) models, where we can have an expert just for the reasoning phase.
The future is bright. Stay tuned for the next advancements.
